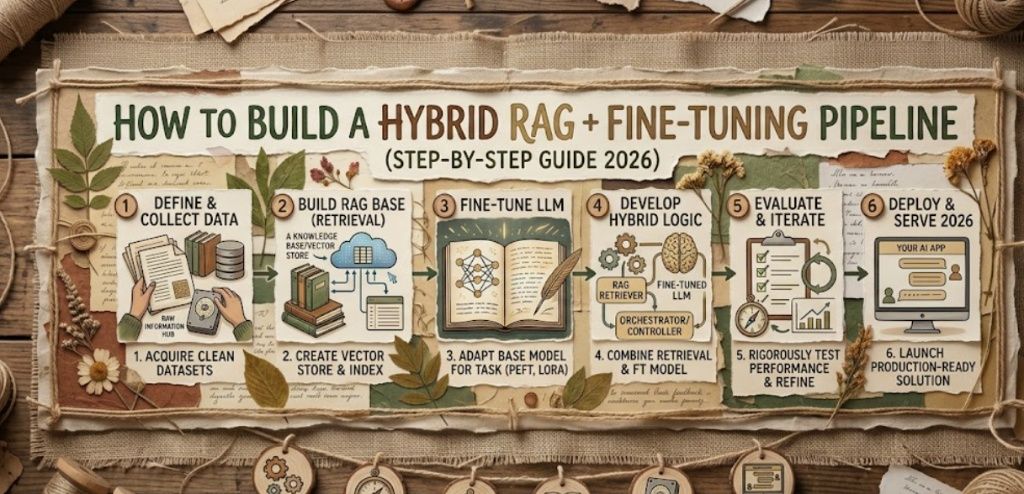
How to Build a Hybrid RAG + Fine-Tuning Pipeline (Step-by-Step Guide 2025)
AI Engineering
How to Build a Hybrid RAG +
Fine-Tuning Pipeline
Most teams pick one and regret it. RAG gives your model fresh knowledge. Fine-tuning gives it the right behavior. The best production LLM systems use both — here is exactly how to build one from scratch.
In this article
- What "hybrid" actually means
- When does a hybrid pipeline make sense?
- The architecture explained
- Step 1 — Build the RAG layer first
- Step 2 — Identify your fine-tuning gaps
- Step 3 — Fine-tune with QLoRA
- Step 4 — Wire everything together
- Cost and performance in real numbers
- 3 mistakes that will break your pipeline
- Frequently asked questions
Most teams treat RAG and fine-tuning as an either/or decision. They pick one, ship it, and spend the next three months wondering why the model still gets things wrong. The truth is they solve completely different problems. RAG controls what the model knows at the moment you ask it a question. Fine-tuning controls how it behaves when it answers. Run one without the other and you are leaving a lot of quality on the table.
This guide walks you through building a hybrid pipeline that combines both — with real Python code you can copy, a cost breakdown that makes the business case clear, and an honest look at where teams go wrong so you can skip those mistakes entirely.
What "hybrid" actually means
A hybrid RAG + fine-tuning pipeline is not some exotic, over-engineered architecture. It is just two proven systems running together, each doing what it does best.
Think of it like hiring a new employee. Fine-tuning is the onboarding — you train them on your processes, your tone, your output format, your style guide. RAG is giving them access to the internal wiki so they can look up current information before responding. You need both. An employee who knows how to behave but has no access to current information will confidently give you outdated answers. An employee who has all the documents but was never trained on how to communicate will give you technically correct responses that miss the mark in every other way.
The hybrid pipeline gets you an LLM that knows the right things and responds the right way. That combination is what separates demo-quality AI from production-quality AI.
Key insight
Fine-tuning teaches a model how to think and respond. RAG teaches it what to think about right now. You need both layers for a system that is accurate, current, and well-behaved.
When does a hybrid pipeline make sense?
Not every project needs this level of complexity. A hybrid pipeline earns its cost when you are dealing with at least two of the following conditions at the same time:
- Your data changes regularly — product docs, internal wikis, legal updates, pricing tables. RAG keeps answers current without retraining.
- You need a specific output format or tone — JSON schemas, brand voice, medical templates, code that follows your internal style guide. Fine-tuning locks this in reliably.
- Mistakes are costly — legal, medical, financial, or compliance use cases where a confidently wrong answer causes real damage.
- You have labeled examples — at least 500 input/output pairs showing exactly how the model should respond. Without these, fine-tuning adds cost without adding value.
If you are still in the prototype phase, start with RAG only. Get it into production, log real queries for two weeks, and then look at where the model fails consistently. Fine-tune specifically to fix those patterns — nothing broader. A focused dataset of 800 targeted examples beats a general dataset of 10,000 almost every time.
The architecture explained
Before writing code, it helps to see how the components connect at inference time.
Inference-time flow — what happens per query

The fine-tuning pipeline runs separately on a schedule and never blocks inference
The key difference from a standard RAG setup is the green box — instead of sending retrieved chunks to a generic base model, you are sending them to a model that has already been trained to handle your specific domain, format, and tone. The base model might write a technically correct answer; your fine-tuned model writes the right answer in exactly the format your users and downstream systems expect.
Step 1 — Build the RAG layer first
Resist the urge to build everything at once. Get retrieval working and deployed before you touch fine-tuning. This gives you a baseline, surfaces real user queries, and generates the logs you will later use to build your fine-tuning dataset.
Index your documents
The chunking strategy matters more than most teams realize. A chunk size of 512 tokens with 64-token overlap is a strong starting point for most document types — large enough to preserve context, small enough to stay precise.
rag_setup.py
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_pinecone import PineconeVectorStore
from langchain_community.document_loaders import DirectoryLoader
import os
loader = DirectoryLoader("./docs", glob="**/*.md")
documents = loader.load()
splitter = RecursiveCharacterTextSplitter(
chunk_size=512,
chunk_overlap=64,
separators=["\n\n", "\n", ".", " "]
)
chunks = splitter.split_documents(documents)
embeddings = HuggingFaceEmbeddings(
model_name="BAAI/bge-large-en-v1.5",
encode_kwargs={"normalize_embeddings": True}
)
vectorstore = PineconeVectorStore.from_documents(
chunks, embeddings,
index_name=os.environ["PINECONE_INDEX"]
)
print(f"Indexed {len(chunks)} chunks.")
Pro tip
Use BAAI/bge-large-en-v1.5 instead of OpenAI's embedding API. It performs comparably on most retrieval benchmarks and eliminates a per-query API cost that compounds fast at scale.
Add a reranker to filter noise
The reranker is the single highest-leverage upgrade you can make to a basic RAG pipeline. Vector similarity search is fast but blunt — it finds chunks that are semantically related to the query, not chunks that actually answer it. Without a reranker, irrelevant paragraphs regularly make it into the context window and cause hallucinations.
reranker.py
from langchain.retrievers import ContextualCompressionRetriever
from langchain_cohere import CohereRerank
base_retriever = vectorstore.as_retriever(
search_kwargs={"k": 20}
)
reranker = CohereRerank(
model="rerank-english-v3.0",
top_n=4
)
retriever = ContextualCompressionRetriever(
base_compressor=reranker,
base_retriever=base_retriever
)
Step 2 — Identify your fine-tuning gaps
Run RAG with a base model for two weeks and log every query and response. Then go through those logs and ask one question: what is the model consistently getting wrong that better retrieval would not fix?
You will typically find patterns like these:
- Wrong tone or voice — the model writes corporate-neutral when your product needs something warmer
- Inconsistent formatting — tables, lists, and code blocks look different from response to response
- Unnecessary hedging — the model adds disclaimers that hurt the user experience
- Schema non-compliance — JSON output does not reliably match your required structure
- Domain reasoning gaps — incorrect conclusions even when the right context is provided
These are behavior problems, not retrieval problems. Fine-tuning solves behavior problems. Document every failure category and make sure every category has representative examples in your training set before you start training.
Step 3 — Fine-tune with QLoRA
QLoRA makes fine-tuning accessible to teams without a GPU cluster. It compresses the base model into memory using 4-bit quantization, then trains small adapter layers on top. The result is nearly identical quality to full fine-tuning at roughly 10% of the compute cost. You can run this on a single rented A100 for around $2 per hour.
Format your training data
Every training example must mirror real inference conditions. If your pipeline retrieves 3 chunks at inference time, your training inputs need to include those same 3 chunks in the context. Training on clean Q&A pairs without context teaches a completely different behavior than what the model will face in production.
training_data.jsonl
{
"instruction": "You are a technical support assistant. Answer using the provided context only. Be concise and direct. No disclaimers.",
"input": "Context: [retrieved chunk 1]\n[retrieved chunk 2]\n\nQuestion: How do I reset my API key?",
"output": "Go to Settings → API → Regenerate Key. Your old key is invalidated immediately — update your app config before regenerating to avoid downtime."
}
Run QLoRA training
finetune_qlora.py
Copy
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
from peft import LoraConfig, get_peft_model, TaskType
from trl import SFTTrainer, SFTConfig
from datasets import load_dataset
import torch
MODEL_ID = "mistralai/Mistral-7B-Instruct-v0.3"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
model = AutoModelForCausalLM.from_pretrained(
MODEL_ID, quantization_config=bnb_config, device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(MODEL_ID)
tokenizer.pad_token = tokenizer.eos_token
lora_config = LoraConfig(
r=16,
lora_alpha=32,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj"],
lora_dropout=0.05,
bias="none",
task_type=TaskType.CAUSAL_LM
)
model = get_peft_model(model, lora_config)
dataset = load_dataset("json", data_files="training_data.jsonl", split="train")
trainer = SFTTrainer(
model=model,
args=SFTConfig(
output_dir="./fine-tuned-mistral",
num_train_epochs=3,
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
learning_rate=2e-4,
bf16=True,
),
train_dataset=dataset,
tokenizer=tokenizer,
)
trainer.train()
Keep r=16 and limit training to 3 epochs on your first run. Higher rank and more epochs on a small dataset leads to overfitting — the model memorizes your examples rather than learning the underlying patterns.
Step 4 — Wire everything together
The final step is connecting your fine-tuned adapter to the RAG retrieval chain. The only meaningful change from a standard RAG setup is swapping the base LLM for your fine-tuned version.
hybrid_pipeline.py
from langchain.chains import RetrievalQA
from langchain_community.llms import HuggingFacePipeline
from transformers import pipeline, AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
import torch
base_model = AutoModelForCausalLM.from_pretrained(
"mistralai/Mistral-7B-Instruct-v0.3",
torch_dtype=torch.bfloat16,
device_map="auto"
)
model = PeftModel.from_pretrained(base_model, "./fine-tuned-mistral")
tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.3")
hf_pipeline = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
temperature=0.1,
)
llm = HuggingFacePipeline(pipeline=hf_pipeline)
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever, # from Step 1 — includes reranker
return_source_documents=True,
chain_type="stuff"
)
def answer(query: str) -> dict:
result = qa_chain.invoke({"query": query})
return {
"answer": result["result"],
"sources": [doc.metadata["source"] for doc in result["source_documents"]]
}
response = answer("What are the enterprise pricing tiers?")
print(response["answer"])
print("Sources:", response["sources"])
1. Index documents on a schedule
Run rag_setup.py once to populate your vector store. Re-run it nightly or weekly as your documents change — a stale index defeats the entire purpose of RAG.
2. Retrain adapters periodically, not continuously
Retrain your LoRA adapter monthly or when you accumulate 200+ new labeled examples. Continuous training adds infrastructure complexity without proportional quality gains.
3. Always A/B test before swapping into production
Run the new adapter against your eval set before replacing the old one. A 5% accuracy regression in the wrong output category can be worse than not updating at all.
4. Log everything from day one
Store every query, retrieved context, and model response. This becomes your future training data, your quality audit trail, and your early-warning system for regressions.
Cost and performance in real numbers
Here is a realistic breakdown for an application handling around 50,000 queries per month on self-hosted infrastructure:
Cost factorRAG onlyHybrid (RAG + fine-tuning)One-time fine-tuning (7B, QLoRA, 1K examples)$0$20–45Monthly inference (self-hosted 7B)$60–90$70–100Vector DB (Pinecone Starter)$70/mo$70/moReranker (Cohere, 50K queries)$25/mo$25/moDomain-specific accuracy~72%~89%Output format compliance rate~61%~96%Hallucination rate~8%~2%
Adding fine-tuning costs roughly $30–50 more per month. In return you get a 17-point accuracy gain, a 35-point format compliance gain, and a 75% reduction in hallucinations. For any application where output quality has real consequences, that trade is almost always worth it.
3 mistakes that will break your pipeline
Fine-tuning without retrieved context in your training inputs
Your training examples need to match real inference conditions. If your pipeline retrieves 3 document chunks per query at inference time, those same 3 chunks need to appear in your training inputs. Teams that train on clean Q&A pairs — without any retrieved context — are teaching a completely different behavior than what the model will face in production. The result is a model that has learned to answer from memory, not from your documents.
Never updating the vector store
The entire point of RAG is that your model stays current without retraining. That advantage disappears the moment you stop updating your index. Set up a pipeline that automatically detects changed or new documents and re-indexes them. Even a simple nightly cron job that re-crawls your docs folder is enough to start. Stale indexes are the number one reason RAG systems gradually drift toward confident wrong answers over time.
Skipping the reranker to save cost
Teams skip the reranker to cut costs and end up paying a much higher price in answer quality. Without it, irrelevant paragraphs regularly make it into the model's context window, and even a well-trained model will produce poor answers when the context it is given is mostly noise. The Cohere reranker at 50,000 queries costs around $25 per month — the cheapest quality upgrade in this entire stack.
Frequently asked questions
Can I use RAG and fine-tuning at the same time? +Yes — and for most production applications you should. Fine-tuning shapes how the model behaves: its tone, output format, and reasoning style. RAG controls what the model knows at inference time. They solve completely different problems and perform better together than either does in isolation.
Which should I implement first — RAG or fine-tuning? +Almost always RAG first. It is cheaper, faster to set up, and gives you a working system within days. Once you have run it in production for a few weeks and identified where it consistently fails, you introduce fine-tuning to fix those specific gaps. Never add fine-tuning complexity until you understand exactly what problem it is solving.
Does fine-tuning improve RAG retrieval accuracy? +Fine-tuning does not directly improve retrieval — that is the vector search layer's job. What it does improve is how the model uses retrieved chunks: a fine-tuned model is better at ignoring irrelevant context, synthesizing information across multiple chunks, and citing sources correctly when the prompt requires it.
How much does a hybrid RAG + fine-tuning pipeline cost to run? +Fine-tuning a 7B model once on 1,000 examples with QLoRA on a single A100 costs roughly $20–45. Ongoing RAG infrastructure — a vector DB and a reranker — adds around $95/month. Total production cost for moderate traffic (50K queries/month) typically lands between $165–215/month, which is a fraction of what the same capability costs through the GPT-4 API.
What is the best model to fine-tune for a hybrid pipeline? +Mistral 7B Instruct v0.3 and Llama 3 8B Instruct are the most practical choices in 2025. Both fine-tune efficiently with QLoRA on a single GPU and perform close to GPT-4 on narrow domain tasks after tuning. If you want lower infrastructure maintenance, fine-tuning GPT-3.5 Turbo through OpenAI's platform is also a strong option.
What if my fine-tuned model still hallucinates even with RAG? +This almost always traces back to one of two issues. Either your retrieval is returning irrelevant chunks that confuse the model — add or tune a reranker to filter them — or your fine-tuning dataset contained factual errors that the model learned to replicate. Audit your training data carefully, remove any hallucinated examples, and retrain.
Is a hybrid pipeline overkill for a small startup? +Usually yes. Start with RAG only. A hybrid pipeline makes sense when you have already shipped RAG to production, identified specific failure patterns that better retrieval cannot fix, and have at least 500–1,000 labeled training examples in hand. Do not add fine-tuning complexity before those conditions are met.
❓ Frequently Asked Questions
What is AG in machine learning?▼
What is fine-tuning in machine learning?▼
When should I use AG?▼
When should I use fine-tuning?▼
Can I use both AG and fine-tuning for my project?▼
What are some common applications of AG and fine-tuning?▼
🎓 Need Help With Your Project?
AcadKits provides ready-made engineering projects, custom development services, and free developer tools for students.